
In questo post vedremo come configurare Replication in Sql Server 2016, ma prima di illustrare tutti i passaggi necessari per la configurazione occorre sapere di cosa stiamo parlando.
Sommario
Replication in Sql Server 2016: cos’è?
Microsoft SQL Server (MS SQL Server) è un software di gestione dei database che può essere installato nei sistemi operativi Windows Server e Linux .
I database sono importanti per tutti i tipi di aziende e molte soluzioni software utilizzano database che possono essere centralizzati e distribuiti. La disponibilità di database e la pertinenza dei dati sono fondamentali per le aziende, rendendo necessario il backup e la replica dei database.
Con la replica di MS SQL Server è possibile creare una copia identica del database primario o sincronizzare le modifiche tra più database e mantenere la coerenza e l’integrità dei dati.
In questo post di blog sono elencati i tipi di replica di SQL Server, viene illustrato il funzionamento della replica in SQL Server e viene descritto come eseguire la replica di SQL Server.
Terminologia utilizzata per la replica di MS SQL Server
Prima di configurare replication in Sql Server, esaminiamo innanzitutto brevemente i termini principali e i modelli di replica.
Maggiori informazioni sono disponibile nella documentazione Microsoft.
Gli articoli sono le unità di base da replicare, ad esempio tabelle, procedure, funzioni e visualizzazioni. Gli articoli possono essere ridimensionati verticalmente o orizzontalmente utilizzando filtri. È possibile creare più articoli per lo stesso oggetto.
Una pubblicazione è una raccolta logica di articoli. Si tratta dell’insieme finale di entità del database designato per la replica.
Un filtro è un insieme di condizioni per un articolo. La funzionalità di replication in Sql Server consente di utilizzare filtri e selezionare entità personalizzate per la replica, riducendo di conseguenza il traffico, la ridondanza e la quantità di dati archiviati in una replica di database. Ad esempio, è possibile selezionare solo le tabelle e i campi più critici utilizzando i filtri e replicare solo questi dati.
Esistono tre ruoli principali nella replica del database MS SQL: distributore, editore e sottoscrittore.
Un distributore è un’istanza del database MS SQL configurata per la raccolta di transazioni dalle pubblicazioni e per la distribuzione ai sottoscrittori. Un distributore funge da database per l’archiviazione delle transazioni replicate. Un database del distributore può essere considerato come editore e distributore contemporaneamente. Nel modello di server di distribuzione locale, una singola istanza di MS SQL Server esegue sia il server di pubblicazione che il server di distribuzione. Un modello di distributore remoto può essere utilizzato quando si desidera che i sottoscrittori siano configurati per l’utilizzo di una singola istanza di MS SQL Server per ottenere pubblicazioni diverse (distribuzione centralizzata). In questo modello, il server di pubblicazione e il server di distribuzione vengono eseguiti su server diversi.
Un editore è la copia principale del database in cui è configurata la pubblicazione, che rende disponibili i dati ad altri server MS SQL configurati per l’utilizzo nel processo di replica. Il server di pubblicazione può avere più di una pubblicazione.
Un sottoscrittore è un database che riceve i dati replicati da una pubblicazione. Un sottoscrittore può ricevere dati da più di un editore e pubblicazione. Un modello a server di sottoscrizione singolo viene utilizzato quando è disponibile un server di sottoscrizione. Un modello multi-sottoscrittore viene utilizzato quando più sottoscrittori sono connessi a una singola pubblicazione.
Gli agenti sono componenti di MS SQL Server che possono fungere da servizi in background per il sistema di gestione dei database relazionali e vengono utilizzati per pianificare l’esecuzione automatica dei processi, ad esempio il backup e la replica del database MS SQL. Esistono cinque tipi di agenti: Agente snapshot, Agente lettore di log, Agente di distribuzione, Agente di merge e Agente lettore code.
Subscription è una richiesta per una copia di una pubblicazione che deve essere consegnata al sottoscrittore. La subscription viene utilizzata per definire i dati di pubblicazione che devono essere ricevuti e dove e quando tali dati verranno ricevuti. Esistono due tipi di subscription: push and pull.
Subscription Push: i dati modificati vengono trasmessi forzatamente da un server di distribuzione al database del server di sottoscrizione. Non è necessaria alcuna richiesta da parte dell’abbonato.
Subscription pull: i dati modificati effettuati nel server di pubblicazione vengono richiesti da un sottoscrittore. L’agente viene eseguito sul lato del server di sottoscrizione.
Un database di sottoscrizione è un database di destinazione nel modello di replica MS SQL.
I metadati sono i dati utilizzati per descrivere le entità del database. Esiste un’ampia gamma di funzioni di metadati integrate che consentono di restituire informazioni sull’istanza di MS SQL Server, sulle istanze del database e sulle entità del database.
Nel modello di più server di pubblicazione, o più sottoscrittori, il server di pubblicazione può fungere da server di sottoscrizione in uno dei server SQL MS. Assicurarsi di evitare potenziali conflitti di aggiornamento quando si utilizza questo modello di replication in Sql Server.

Tipi di Replication in Sql Server
Replication in Sql Server è una tecnologia per copiare e sincronizzare i dati tra database in modo continuo o regolare a intervalli pianificati. Per quanto riguarda la direzione di replica, la replica di MS SQL Server può essere: unidirezionale, uno-a-molti, bidirezionale e molti a uno. Esistono quattro tipi di replica di MS SQL Server: replica snapshot, replica transazionale, replica peer-to-peer e replica di tipo merge.
Replica snapshot
La replica snapshot viene utilizzata per replicare i dati esattamente come appaiono nel momento in cui è stato creato lo snapshot del database. Questo tipo di replica può essere utilizzato quando i dati vengono modificati raramente; quando non è fondamentale avere una replica di database precedente a un database master; o un grande volume di modifiche viene apportato in un breve periodo di tempo. Non viene eseguito alcun rilevamento delle modifiche per la replica snapshot. Ad esempio, la replica snapshot può essere utilizzata quando i tassi di cambio o i listini prezzi vengono aggiornati una volta al giorno e devono essere distribuiti da un server principale ai server delle succursali.

Replica transazionale
La replica transazionale è la replica automatica periodica quando i dati vengono distribuiti da un database master a una replica di database in tempo reale (o quasi in tempo reale). La replica transazionale è più complessa della replica snapshot. Non solo viene replicato lo stato finale di un database, ma vengono replicate anche tutte le transazioni effettuate, il che consente di monitorare l’intera cronologia delle transazioni nella replica del database. All’inizio del processo di replica transazionale, uno snapshot viene applicato al server di sottoscrizione e quindi i dati vengono continuamente trasferiti da un database master a una replica del database dopo essere stati modificati. La replica transazionale è ampiamente utilizzata come replica uni-way.

Esempi e casi d’uso per la replica transazionale:
- Creazione di un server di database con una replica di database che può essere utilizzata per eseguire il failover in caso di errore di un server di database principale.
- Ottenere report sulle operazioni eseguite nelle filiali utilizzando più editori nelle filiali e un abbonato nella sede principale.
- Le modifiche devono essere replicate il prima possibile dopo che si verificano.
- I dati in un database di origine vengono modificati frequentemente.
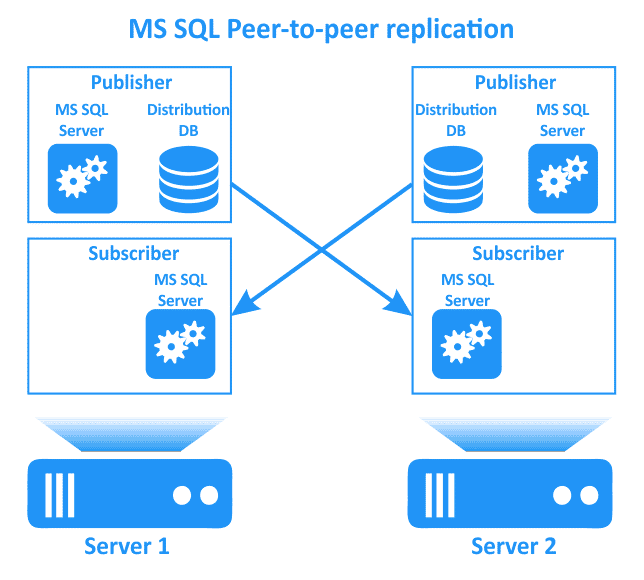
Replica peer-to-peer
La replica peer-to-peer viene utilizzata per replicare i dati del database in più sottoscrittori contemporaneamente. Questo tipo di replication in Sql Server può essere utilizzato quando i server di database sono distribuiti in tutto il mondo. È possibile apportare modifiche a qualsiasi server di database. Le modifiche vengono propagate a tutti i server di database. La replica peer-to-peer può aiutare a scalare un’applicazione che utilizza un database. Il principio di funzionamento principale si basa sulla replica transazionale.
Replica di tipo merge
La replica di tipo merge è un tipo di replica bidirezionale che viene solitamente utilizzata in ambienti da server a client per sincronizzare i dati tra i server di database quando non possono essere connessi continuamente. Quando viene stabilita la connessione di rete tra entrambi i server di database, gli agenti di replica di tipo merge rilevano le modifiche apportate in entrambi i database e modificano i database per sincronizzarne e aggiornarne lo stato. La replica di tipo merge è simile alla replica transazionale, ma i dati vengono replicati dal server di pubblicazione al server di sottoscrizione e viceversa.

Questo tipo di replica del database è il più complesso di tutti i tipi di replica di MS SQL Server e viene utilizzato raramente. Ad esempio, la replica di tipo merge può essere utilizzata da più archivi peer che funzionano con un magazzino condiviso.
Ogni negozio è autorizzato a modificare le informazioni nel database del magazzino e allo stesso tempo tutti i negozi devono avere lo stato aggiornato dei loro database dopo la spedizione della merce o la consegna delle forniture al magazzino. La replica di tipo merge può essere utilizzata nei casi in cui le informazioni aggiornate devono essere disponibili contemporaneamente per il database principale (o centrale) e i database di succursale.

